|
Support |
| ||||
| ||||||
|
The new Intel Pentium 4 processor is the latest generation of the Intel IA-32 architecture. Formerly code-named "Willamette," the Pentium 4 processor introduces significant architecture advances over the previous 32-bit P6 processor family consisting of the Pentium Pro, Pentium II, and Pentium III processors. This article begins with a review of the evolution of the IA-32 architecture and then discusses the software and hardware architectural changes that the Pentium 4 processor family brings to desktop, workstation, and server systems. IA-32 EvolutionThe IA-32 architecture essentially began with the 80386 processor. Although the basic set of 32-bit instructions have remained the same, there have been architecture changes and instruction-set enhancements along the way. The 80486 processor added an internal cache, instruction pipelining, and an integrated math coprocessor. Next, the Pentium processor introduced a superscalar microarchitecture that allowed it to execute multiple instructions in parallel. In addition, Intel split the internal level 1 (L1) cache of the Pentium processor into separate instruction and data caches to improve code performance. The Pentium Pro introduced the concept of a backside level 2 (L2) cache that removed many of the bandwidth and latency limitations of an L2 cache on the frontside bus (FSB) as seen in prior processors. In addition, the Pentium Pro featured the ability to convert complex instruction set computer instructions (CISC) into micro-ops, which were then executed on a reduced instruction set computer (RISC) core. The Pentium Pro also contained more execution units to extend its superscalar capabilities and a longer pipeline to increase the frequency above previous generations. Intel released an enhanced version of the Pentium processor, the Pentium processor with MMXTM technology, in 1997. The Pentium MMX incorporated multimedia extensions (MMX) to the basic IA-32 instruction set. This allowed software developers to perform more digital signal processing (DSP)-like functions on the processor to improve graphics and sound capabilities. The Intel Pentium II processor improved on the Pentium Pro by changing from a multichip module (MCM) to a single-edge connector cartridge (SECC). The SECC allowed Intel to move the P6 family into mass production. At this point, MMX technology was also introduced in the P6 processor family. The Pentium III processor added Streaming Single Instruction Multiple Data (SIMD) Extensions (SSE) to the P6 family. SIMD operations allow code developers to perform identical operations on multiple pieces of data in parallel. This capability allows many iterative calculations to be performed simultaneously, reducing the overall execution time. SSE added 68 new instructions, including 45 new floating-point operations, 11 SIMD integer instructions, and 5 cache-management instructions. Pentium 4 Processor NetBurstTM MicroarchitectureThe Pentium 4 processor's "NetBurst" microarchitecture enables significant hardware and software advances over previous IA-32 processors. This new microarchitecture allows greater scalability and internal performance enhancements over the current Pentium III architecture. Hardware Architectural ChangesThe Pentium 4 processor is
initially targeted for the same 0.18u process technology used for the
Pentium III, but will be migrated to future process technologies as they
become feasible. The hardware changes include:
Hyper Pipelined Technology describes the Pentium 4 processor internal pipeline, which has been extended from the 10-stage pipeline in the Pentium III to a 20-stage pipeline shown in Figure 1. Increasing the number of pipeline stages reduces the number of gates per stage, which allows a higher core frequency and greater frequency scalability for the future. (See sidebar, "Why Can Longer Pipelines Achieve Higher Frequencies?")
Figure 1. New Pentium 4 Processor 20-Stage Pipeline
Increasing the number of
stages can impact performance because there is additional overhead
associated with the added stages. There is also a higher performance
penalty if the processor incorrectly predicts a code sequence for
execution. These mispredictions require the pipeline to be restarted. To
mitigate performance penalties, Intel has implemented Advanced Dynamic
Execution architecture, an enhanced version of the Dynamic Execution
architecture introduced in the P6 family of processors. In addition, the
Pentium 4 processor includes the new Execution Trace Cache.
The L1 data cache has been
redesigned to increase bandwidth and reduce latency. It is an 8-KB, 4-way
set-associative cache with 64-byte lines. (For an explanation of
set-associative cache, see "An Overview of Cache," http://developer.intel.com/design/intarch/papers/cache6.htm
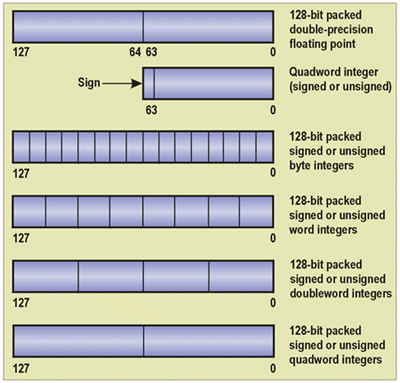
Introduced in the Pentium III with integrated L2 cache, the Advanced Transfer Cache is a 256-KB, 8-way set-associative cache that holds both data and instructions. The Pentium 4 processor has extended this cache architecture to include 128-byte lines, with two 64-byte pieces per line. The cache bus bandwidth is more than double that of the Pentium III; for example, the bandwidth on a 1.5-GHz processor is 48 GB/sec. Rapid Execution EngineThe Rapid Execution Engine is a performance-enhanced arithmetic logic unit (ALU). The ALU has been redefined to execute the most common integer operations in one-half clock, allowing two instructions to be executed in a single clock cycle. This can provide significant performance increases on integer-intensive applications. 400-MHz System BusThe new system bus on the Pentium 4 processor supports a "source-synchronous," "quad-pumped" bus. Source synchronous (also referred to as "clock-forwarded") refers to the ability to propagate the clock or strobe with the data, a requirement for exceeding 200 MHz on the frontside bus. Quad-pumped refers to the ability to transfer four data values per clock. The new system bus is designed to operate with a base clock of 100 MHz; thus, the quad pump produces 400 megatransfers/sec. This increases the bandwidth of the 64-bit system bus to 3.2 GB/sec (compared to 1.0 GB/sec on the Pentium III processor). Enhanced Floating Point/Multimedia EngineThis feature provides significant performance enhancements on standard floating-point operations. The engine has been extended to include a 128-bit port, with a separate floating-point move and data store port. Also included in the enhancements are new data types and instructions for supporting SSE2. Software Architectural Changes: SSE2SSE2 is a set of 144 new instructions that provide advanced capabilities for applications such as 3D graphics, video encoding/decoding, and speech recognition. There are six new data types and three new classes of instructions. SSE2 also includes some changes to take advantage of the advanced hardware features and new data types included in the Pentium 4 processor microarchitecture. In addition, it reuses the eight existing 128-bit extended multimedia (XMM) registers for both SSE2 and SSE operations. SSE2 is fully compatible with current IA-32 software. New Data TypesFigure 2 presents the six new data types included in SSE2. The six new types consist of three classes: a 128-bit packed double-precision floating point, a 64-bit quadword integer, and four 128-bit integer data types. The packed floating-point type allows two IEEE 64-bit double-precision floating-point values to be packed into one double quadword. The 64-bit quadword integer type allows for both signed (i.e., negative or positive) and unsigned values. The 128-bit integer types allow for two quadwords, four doublewords, eight words, or 16-byte integers to be packed into one double quadword.
Figure 2. New Data Types New InstructionsThe 144 new instructions fall into three categories: double-precision floating point, integer, and cache instructions.
The double-precision
floating-point instructions include data movement, arithmetic, comparison,
conversion, logical, and shuffle instructions. Examples include:
Each instruction contains two double-precision floating-point values, and the results are performed in parallel. Thus, both calculations can be performed in parallel. IntegerSSE2 adds several 128-bit
packed-integer instructions. The 128-bit versions of these new
instructions operate on data in the XMM registers, and the 64-bit versions
operate on data in the MMX registers. Example instructions include:
In addition, SSE2 extends all of the 64-bit MMX and SSE integer instructions to operate on 128-bit packed-integer operands located in the XMM registers. CacheAdditional cache instructions over the original SSE instructions allow more control over the caching, loading, and storing of data. Cache instructions are broken down into cache flush, cachability control, memory ordering, and pause instructions. "Cache flush" allows the write-back and invalidate of a single cache line. "Cachability control" instructions provide hints (using "fence" commands) to the cache not to store data that will be accessed once and not reused immediately. The related "memory-ordering" instructions establish the fence commands used in cachability control. "Pause" instructions delay execution of the next instruction for a specified period of time. SSE2 provides powerful extensions to the instruction set for IA-32. These new instructions allow the processor to perform operations on more data in parallel, and the programmer more flexible control over the caching of the data that is being used. Overall, SSE2 allows software to perform better on integer and floating-point calculations that can be executed in parallel. ConclusionThe Pentium 4 processor
delivers significant performance improvements on the following types of
applications and environments:
Dell recently launched Pentium 4 processor-based Dell PrecisionTM WorkStation and high-end DimensionTM systems, to be followed closely by OptiPlexTM systems in early 2001. These are single-processor systems that use the Intel 850 chipset and dual-channel Rambus DRAM. (Intel plans to release "Foster," a dual-processor, larger-cache version of the Pentium 4 processor designed for servers and high-end workstations sometime in 2001.) The architectural improvements in the Pentium 4 processor are expected to allow this Intel processor family to scale frequency and performance for many years. The addition of the SSE2 enhancements provide advanced capabilities for 3D graphics, video encoding/decoding, and speech recognition. Dell believes that the Pentium 4 processor offers a compelling feature set, and will lead the way for next-generation systems, software, and technologies to be incorporated into personal computers. For More InformationFor more information, see
the following website:
Information in this document is subject to change without notice. © 2000 Dell Computer Corporation. All rights reserved. Trademarks used in this text: Dell , the DELL logo, Dell Precision , OptiPlex , and Dimension are trademarks of Dell Computer Corporation; Intel and Pentium are registered trademarks and MMX and NetBurst are trademarks of Intel Corporation. Other trademarks and trade names may be used in this document to refer to either the entities claiming the marks and names or their products. Dell Computer Corporation disclaims any proprietary interest in trademarks and trade names other than its own. | |||||||||
| ||||||||||